Hi!
On a previous post I showed a fantastic Android application called Termux
The app is basically a mini-Linux command-line distro, full of software and things to do.
I use it mostly to write, I connect my usb keyboard and I magically have all the almighty terminal power on my SmartPhone.
With the same text editors you can also read text, actually for that specific matter there are plenty of pagers too.
But these software can’t read all file extensions out of the box, one of these extension are PDF files. So how to read PDF files from the command line?
There are 2 ways to achieve this task, both have the original pdf file converted in another format and both these tools are part of the poppler package:
- pdftotext converts a PDF file to a simple text file
- pdftohtml convert PDF to html
pdftotext can be used with many pagers, editors and browsers as does pdftohtml, however the latter works best with browsers.
As both software can get a pdf file from a URL I’ll use a PDF from the internet (George Orwell 1984, under public domain in Australia) so that you can copy and paste all these command to get the same result as I do.
The software used:
- Converter: pdftotext, pdftohtml (both from the poppler package as said)
- Pagers: more, less, most, vimpager
- Browsers: lynx, w3m, elinks
- Editors: vim, micro, ne, vile, neovim
All these software works out of the box, anything else not listed here may behave in a strange way.
-
pdftotext
use it this way:
pdftotext file.pdf -
This way the output is redirected to stdout and printed on your terminal. Try it out yourself:
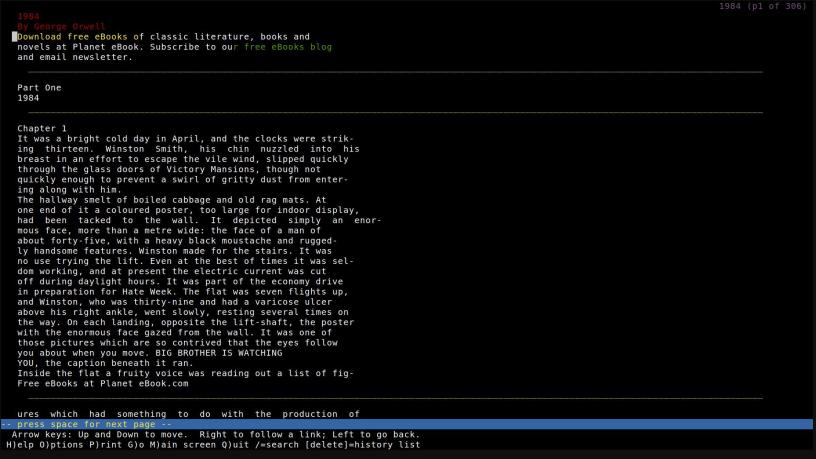
pdftotext http://www.planetebook.com/ebooks/1984.pdf -
Press Ctrl+C to interrupt the command.
As you can see it works! At this point it can be piped to another application.
Pagers:
- more
pdftotext http://www.planetebook.com/ebooks/1984.pdf - |more

- less
pdftotext http://www.planetebook.com/ebooks/1984.pdf - |less

You can also color it up by using tput (also works with more)
tput setaf 3; tput setab 4; pdftotext http://www.planetebook.com/ebooks/1984.pdf - |less

- most
pdftotext http://www.planetebook.com/ebooks/1984.pdf - |most

- vimpager
pdftotext http://www.planetebook.com/ebooks/1984.pdf - |vimpager

Browsers:
- Lynx
pdftotext http://www.planetebook.com/ebooks/1984.pdf - |lynx -stdin

- w3m
pdftotext http://www.planetebook.com/ebooks/1984.pdf - |w3m

- Elinks
pdftotext http://www.planetebook.com/ebooks/1984.pdf - |elinks

Press \ to toggle source or rendered document, it may render without new lines (press v on w3m).
Editors:
- micro
pdftotext http://www.planetebook.com/ebooks/1984.pdf - |micro

- ne
pdftotext http://www.planetebook.com/ebooks/1984.pdf - |ne

- vile
pdftotext http://www.planetebook.com/ebooks/1984.pdf - |vile

- vim
pdftotext http://www.planetebook.com/ebooks/1984.pdf - |vim -

- neovim
pdftotext http://www.planetebook.com/ebooks/1984.pdf - |nvim -

-
pdftohtml
Use it this way:
pdftohtml -stdout -i file.pdf
Always remember the -i option, if you don’t all the pdf images will be saved on your storage to later be accessible from the html (this means tens or even hundreds of images saved on the current directory).
As said this works and looks great with Browsers because they render html (remember to press either \ or v to switch to rendered mode), therefore I’m listing only the browsers here. Anyway the process is the same as above.
Browsers:
- lynx
pdftohtml -stdout -i http://www.planetebook.com/ebooks/1984.pdf |lynx -stdin

- w3m
pdftohtml -stdout -i http://www.planetebook.com/ebooks/1984.pdf |w3m

- elinks
pdftohtml -stdout -i http://www.planetebook.com/ebooks/1984.pdf |elinks

That’s basically how to use these 2 poppler components.
On a future post I’m going to show you how to do the same with epub files.
TA SALÜDE

Wow thanks man this post was helpful
LikeLike